
A few days ago, I snagged a free .news domain from NameCheap and registered hy2.news. Since I didn’t have much use for it, I decided to set up a personal news feed page. Since it’s a dynamic page, I brought out Wordpress and used an RSS plugin to make it happen. The page is live at: Hyruo News
The page is up, but sourcing the RSS feed became an issue. So, I started by trying to scrape the Nodeseek forum, where I’ve been active recently. After hours of effort, I still failed.
Handcrafting an RSSHub Route
The official RSSHub development tutorial is a bit jumpy, but the main process is as follows.
Preliminary Work
- Clone the RSSHub repository (might take over half an hour if your computer is slow)
git clone https://github.com/DIYgod/RSSHub.git - Install the latest version of Node.js (version must be greater than 22) Node.js Official Site
- Install dependencies
pnpm i - Run
pnpm run dev
Developing the Route
Developing the route is relatively simple. Open the RSSHub\lib\routes directory, create a new folder under it, such as nodeseek, and then add two files namespace.ts and custom.ts in that folder.
- namespace.ts File
This file can be copied from the official tutorial or just copied from another folder in the lib\routes directory and modified. Example:
import type { Namespace } from '@/types';
export const namespace: Namespace = {
name: 'nodeseek',
url: 'nodeseek.com',
lang: 'zh-CN',
};
- custom.ts File
This is the main file for developing the route. The filename can be named according to the target website’s structure. Just look at other folders to get the idea. The difficulty lies in the specific content. Example:
import { Route } from '@/types';
import { load } from 'cheerio';
import { parseDate } from '@/utils/parse-date';
import logger from '@/utils/logger';
import puppeteer from '@/utils/puppeteer';
import cache from '@/utils/cache';
export const route: Route = {
path: '/user/:userId',
categories: ['bbs'],
example: '/nodeseek/user/1',
parameters: { userId: 'User ID, e.g., 1' },
features: {
requireConfig: false,
requirePuppeteer: true, // Enable Puppeteer
antiCrawler: true, // Enable anti-crawler
supportBT: false,
supportPodcast: false,
supportScihub: false,
},
radar: [
{
source: ['nodeseek.com/space/:userId'],
target: '/user/:userId',
},
],
name: 'NodeSeek User Topics',
maintainers: ['Your Name'],
handler: async (ctx) => {
const userId = ctx.req.param('userId');
const baseUrl = 'https://www.nodeseek.com';
const userUrl = `${baseUrl}/space/${userId}#/discussions`;
// Import Puppeteer utility class and initialize browser instance
const browser = await puppeteer();
// Open a new tab
const page = await browser.newPage();
// Set request headers
await page.setExtraHTTPHeaders({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
Referer: baseUrl,
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
});
// Visit the target link
logger.http(`Requesting ${userUrl}`);
await page.goto(userUrl, {
waitUntil: 'networkidle2', // Wait for the page to fully load
});
// Simulate scrolling the page (if needed)
await page.evaluate(() => {
window.scrollBy(0, window.innerHeight);
});
// Wait for the post list to load
await page.waitForSelector('a[href^="/post-"]', { timeout: 7000 });
// Get the HTML content of the page
const response = await page.content();
const $ = load(response);
// Extract the post list
let items = $('a[href^="/post-"]')
.toArray()
.map((item) => {
const $item = $(item);
const title = $item.find('span').text().trim();
const link = `${baseUrl}${$item.attr('href')}`;
return {
title,
link,
};
});
// Exclude two fixed links in the footer
const excludedLinks = ['/post-6797-1', '/post-6800-1'];
items = items.filter((item) => !excludedLinks.includes(new URL(item.link).pathname));
// Extract up to 15 posts
items = items.slice(0, 15);
// Print the extracted post list
console.log('Extracted post list:', items); // Debug info
// If the post list is empty, the dynamic content might not have loaded
if (items.length === 0) {
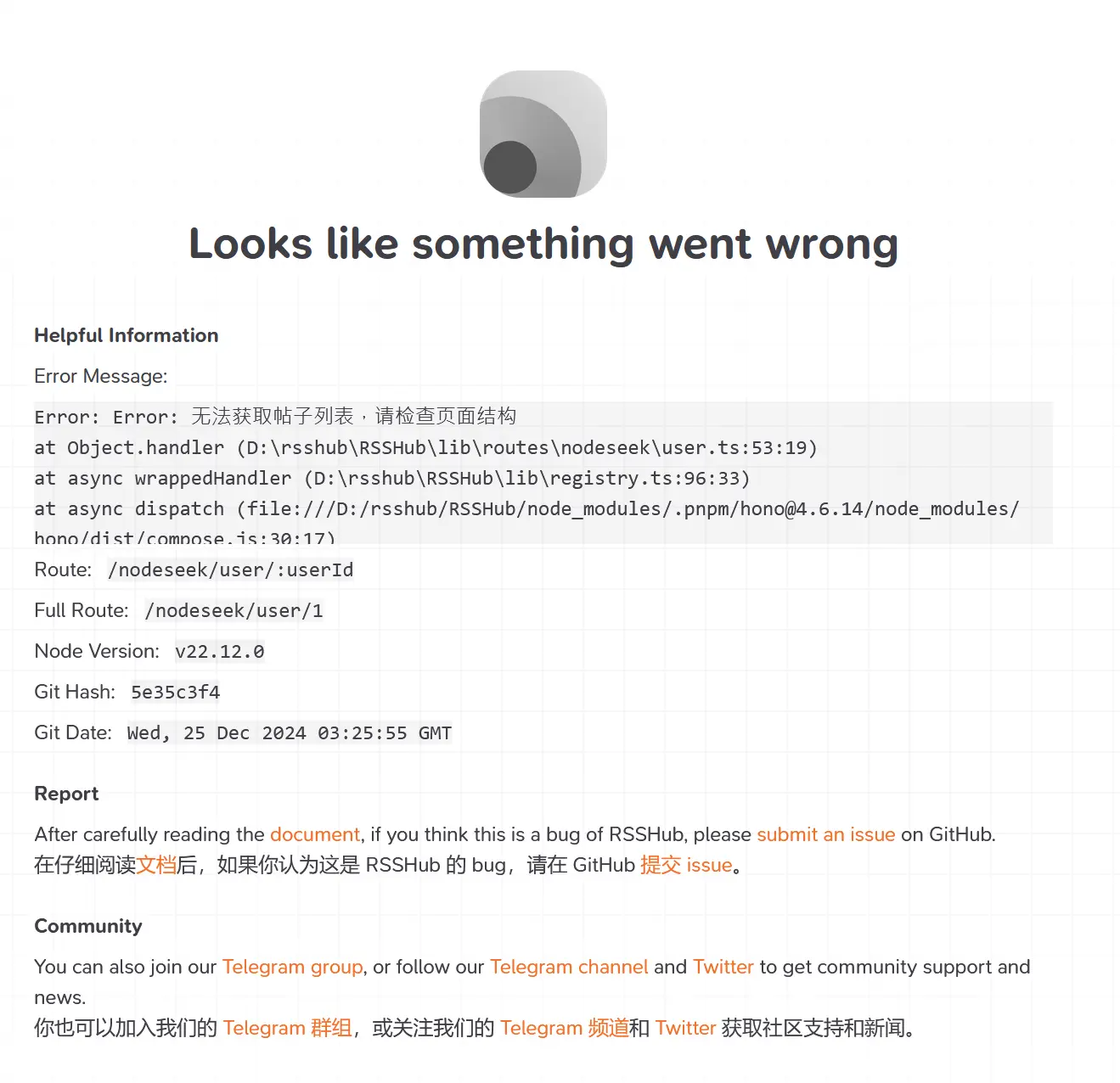
throw new Error('Failed to retrieve post list, please check the page structure');
}
// Get the content of each post
items = await Promise.all(
items.map((item) =>
cache.tryGet(item.link, async () => {
// Open a new tab
const postPage = await browser.newPage();
// Set request headers
await postPage.setExtraHTTPHeaders({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
Referer: baseUrl,
});
// Visit the post link
logger.http(`Requesting ${item.link}`);
await postPage.goto(item.link, {
waitUntil: 'networkidle2', // Wait for the page to fully load
});
// Get the post content
const postHtml = await postPage.content();
const $post = load(postHtml);
item.description = $post('article.post-content').html();
item.pubDate = parseDate($post('time').attr('datetime'));
// Close the post page
await postPage.close();
return item;
})
)
);
// Close the browser instance
await browser.close();
// Return RSS data
return {
title: `NodeSeek User ${userId} Topics`,
link: userUrl,
item: items,
};
},
};
Summary of Main Issues
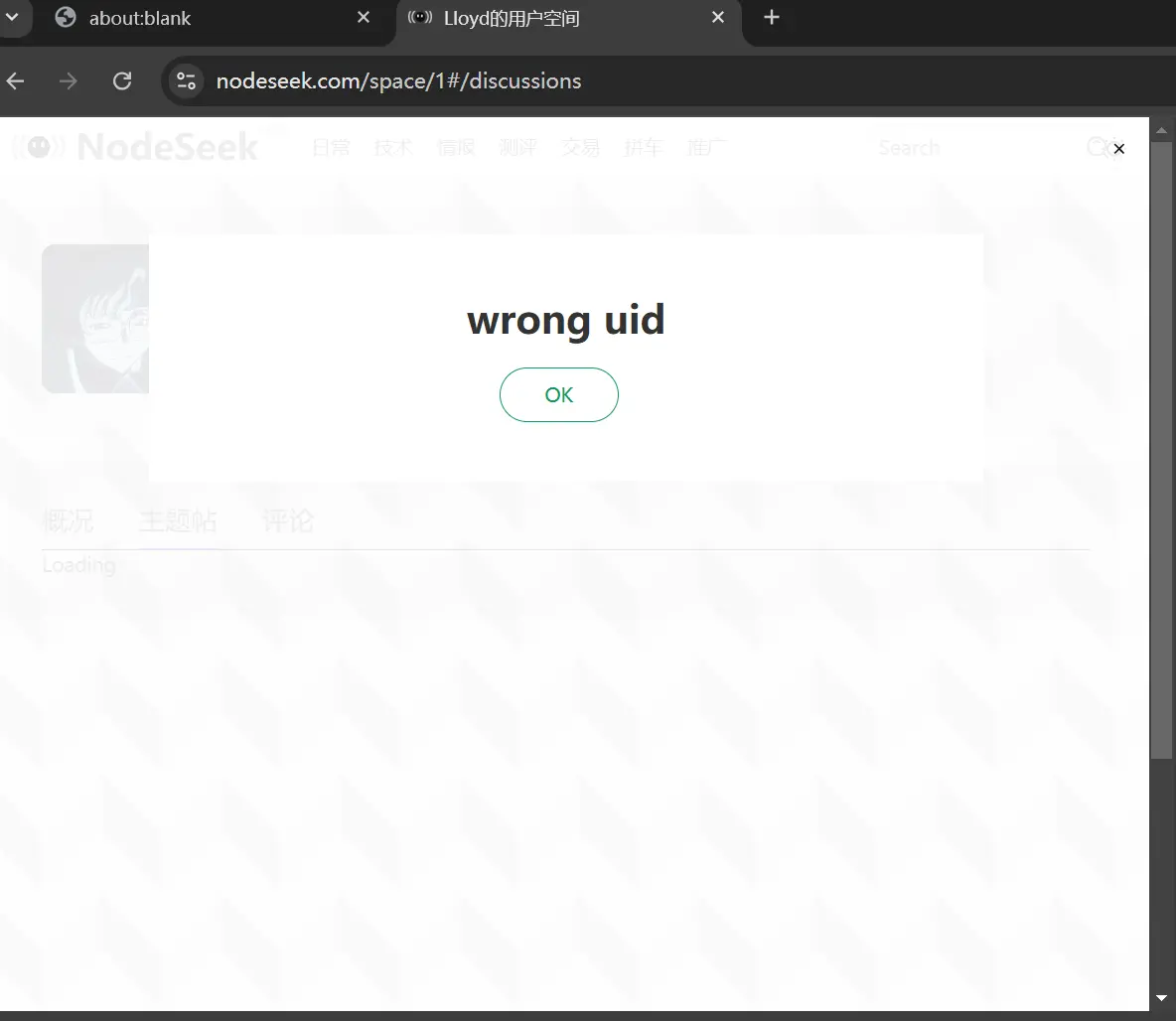
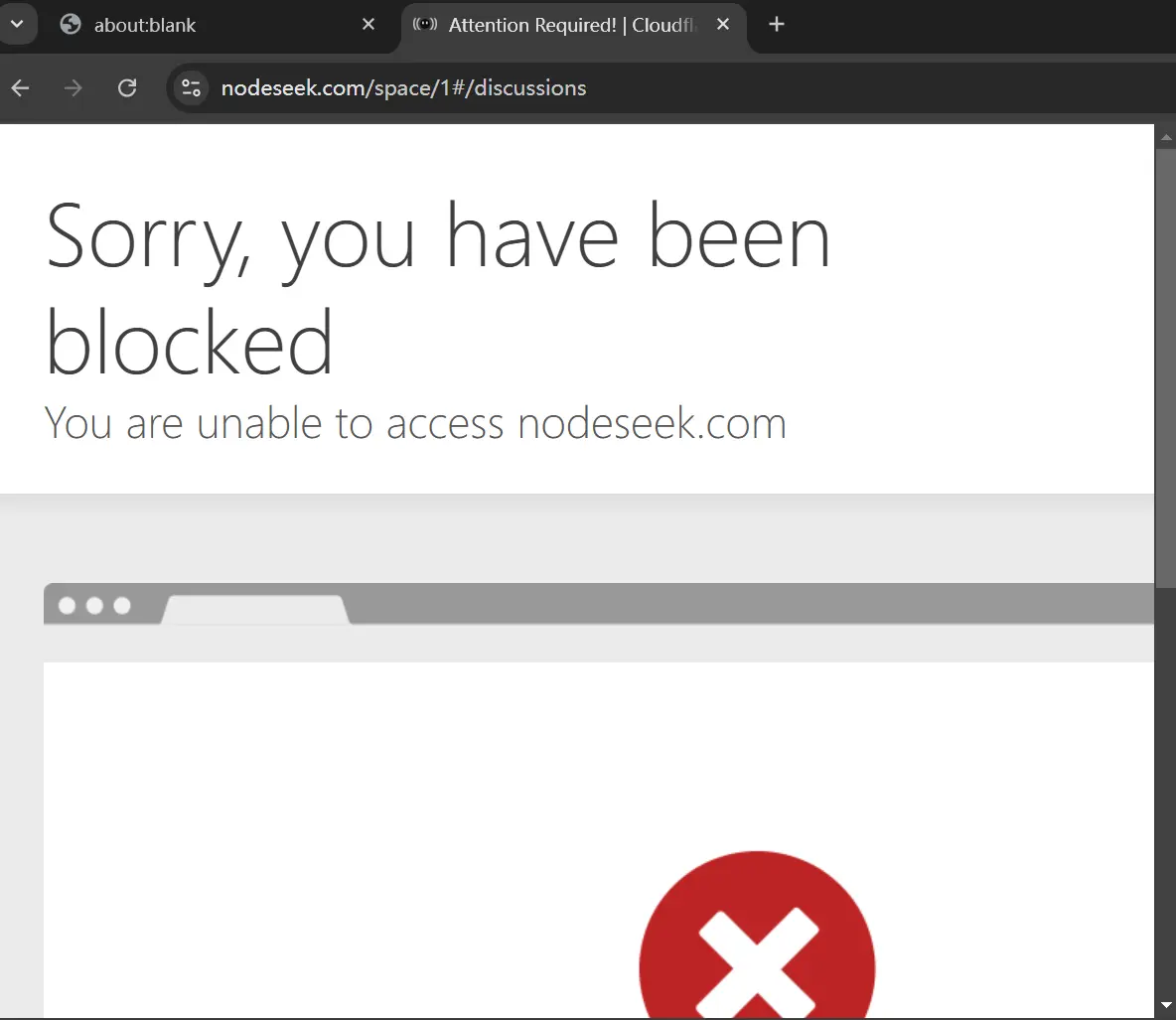
In short, the main reason for the failure in handcrafting the Nodeseek route was the inability to bypass Nodeseek’s anti-crawling measures and Cloudflare’s protection.
The extreme method RSSHub can use is to simulate browser behavior with Puppeteer to counter crawling. However, machine-simulated behavior is easily detected by platforms like Cloudflare.
During local testing, I had about a 50% success rate, and that was with the latest version of Puppeteer. If I used the Puppeteer version from RSSHub’s official dependencies, the success rate was less than 10%. Considering that submitting to RSSHub requires double review, the success rate is just too low.
For now, I have to reluctantly give up.
When It Rains, It Pours
This morning, I woke up to find that the sky had fallen—6 of my free *.US.KG domains were down because the parent domain stopped resolving.
Then, at noon, the sky fell again. The .news domain I had just set up was suspended by the registrar. They sent me an email asking for an explanation of why my personal information changed during the registration process, and then forcibly redirected the NS to an IP address no one recognizes.
Well, that’s my own fault. I messed up during registration.When I directly used the browser’s auto-fill form program, I accidentally filled in all the real information. Then, when I tried to change it back, an error occurred as soon as I made the changes.
PS: In the afternoon, *.us.kg returned to normal. But I feel like I won’t love it anymore.