
Recently, I have been developing an intelligent case analysis application. Since there are no suitable local models capable of achieving the desired analysis results, I can only rely on remote full-scale large models for analysis. However, during this process, how to ensure data security has become a very important topic. My initial idea is to perform data desensitization locally before submitting for remote analysis, and absolutely no cloud upload should occur before data desensitization. Thus, I began a lengthy testing journey.
Trade-offs Between Efficiency and Accuracy in Small Models
Initially, I pursued extreme lightweight solutions and tried pure frontend small models around 20MB, such as ckiplab-bert-tiny-chinese-ner and the even more streamlined ckiplab-albert-tiny-chinese-ner. They were indeed satisfying to use; when I performed batch extraction with 100 test data entries, I found that these small models could almost complete processing on a PC within seconds. However, the processing accuracy was somewhat lacking: many personal names and organization names in the data body were not accurately identified; moreover, some three-character personal names were simultaneously recognized as two different people. Especially when facing cases with colloquial expressions, many colloquial entity names could not be recognized either.
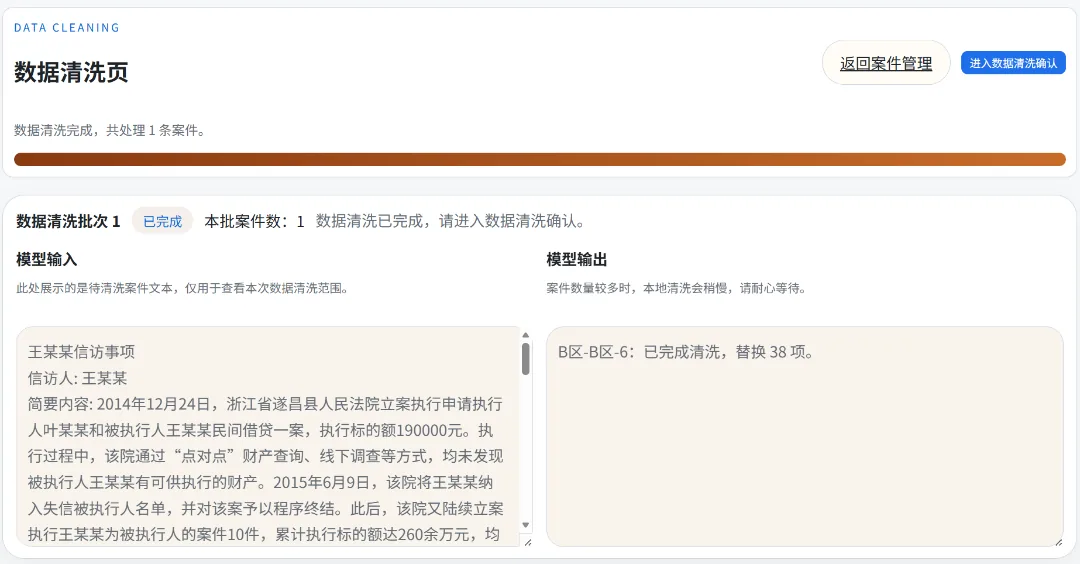
Of course, during the design of this application, I had already considered this situation, so I added a very user-friendly manual review mechanism. The desensitized data from earlier is broken down into individual Chinese characters; clicking on uncompleted desensitization terms automatically adds them to the desensitization database.
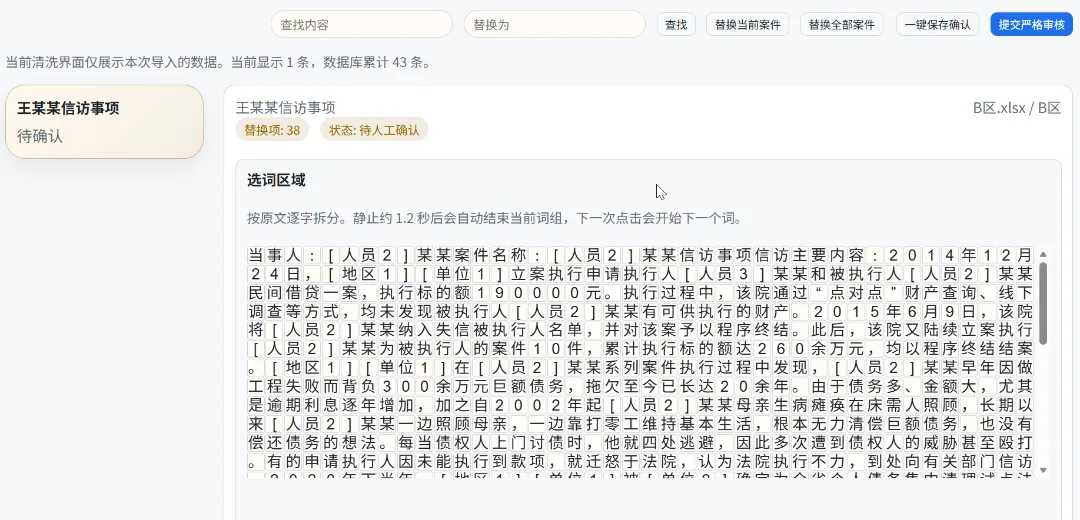
However, the processing efficiency of small models is indeed not high; my actual testing showed that nearly 30% of personal names, abbreviated place names, and company names might fail to be recognized. Especially for some regional abbreviations and organization acronyms mentioned in cases, such NER models can hardly recognize them. And replacing these characters and words all at once can easily cause semantic confusion in the main text. Manual operation is also quite troublesome.
Large Models Place Significant Pressure on Hardware
Subsequently, I turned to the recently popular “small-parameter large models,” namely Qwen3.5:0.8B, and for comparison, also pulled last year’s DeepSeek-R1:1.5B for testing. After all, in a pure CPU environment, this is already the limit of size I can tolerate. I originally thought that the semantic understanding of large models could handle everything, but as it turned out, in entity extraction tasks, they performed extremely unstably. Not only could they not overcome the logical threshold, but long texts also easily lost commands. The only slight improvement was that after disabling Qwen’s think mode, the output finally returned to normal, but during each round of testing, the resulting data remained highly unstable.
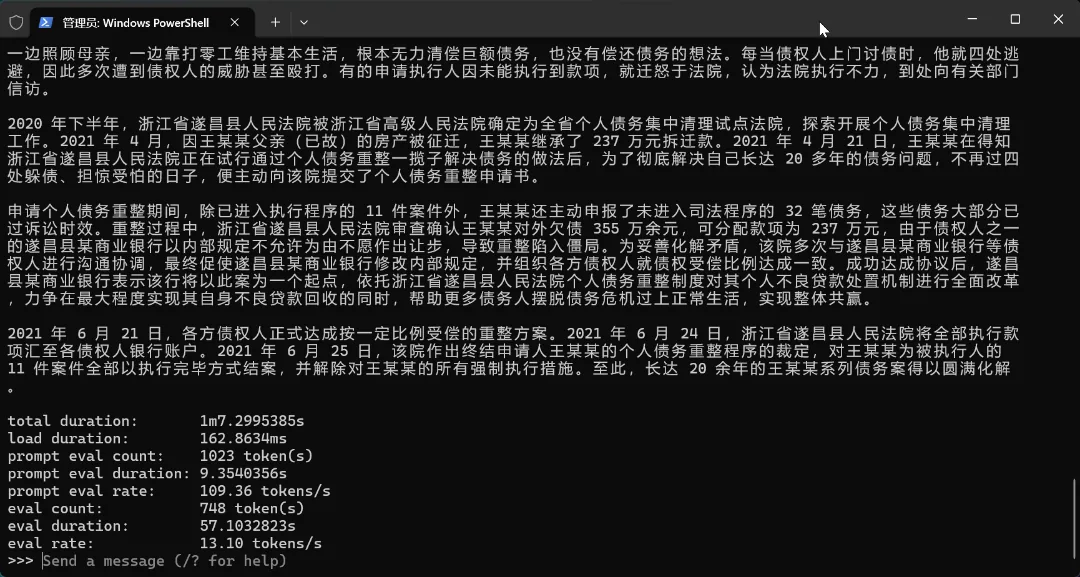
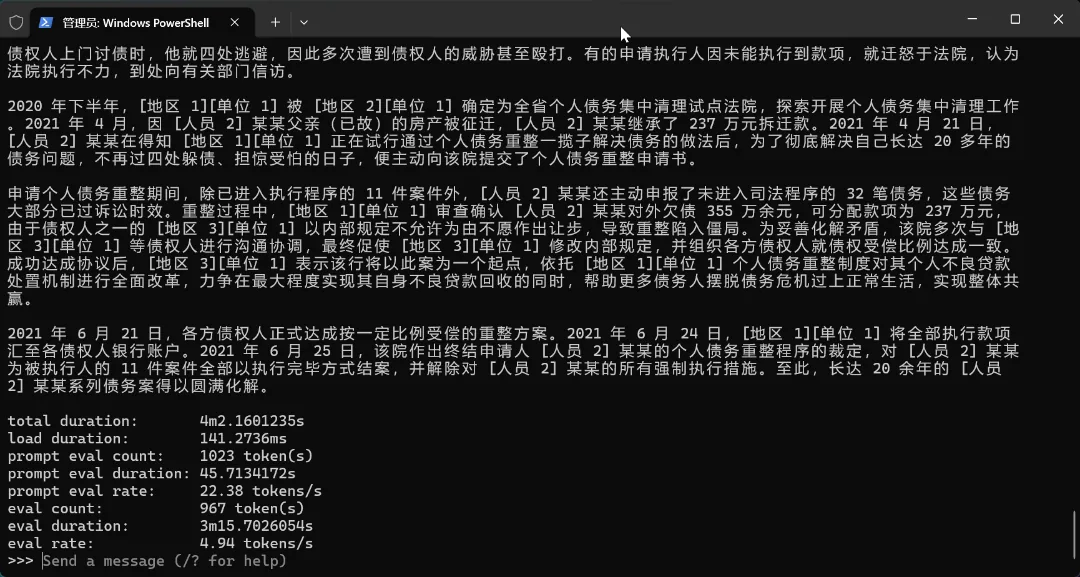
However, the process was not without gains. Unwilling to give up, I tested with Qwen3.5:4B and found that the 4B model performed very well for my long-text desensitization needs—almost as if it were a completely different model from the 0.8B version. However, on the laptop I used for testing, the Ollama version of Qwen3.5:4b had an output efficiency of only 5 tokens/s; even switching to the gguf version could only reach 7 tokens/s, which was still quite uncomfortable to use—a single data entry of under 100 characters took 2 minutes.
| Metric | Ollama (Standard Version) | Unsloth GGUF | Winner |
|---|---|---|---|
| Prompt Preprocessing Speed (Prefill) | 77.38 tok/s | 27.5 tok/s | Ollama (2.8x faster) |
| Text Generation Speed (Decode) | 5.53 tok/s | 8.6 tok/s | Unsloth (1.5x faster) |
| Total Time (Total) | 163.5s | 119.4s | Unsloth (saves approximately 44s) |
| Input Token Count | 754 | 778 | - |
| Generated Token Count | 847 | 779 | - |
Medium-sized NER Models Generally Offer a Better Balance Between Performance and Efficiency
During the development of this project, I also comparatively tested solutions such as RaNER, HanLP, SpaCy, and Siamese-UniNLU. Detailed comparative data was not retained during the process, but based on subjective actual testing, none seemed to fully meet my requirements. For instance, RaNER encountered issues right from the start with long texts, and Siamese-UniNLU also failed on long texts. SpaCy and HanLP repeatedly had problems with text truncation; when judging certain entity names, they often got tangled with surrounding characters.
After repeated trials and adjustments, I finally selected two solutions that appeared to offer a relatively balanced performance and effectiveness:
Pure Local CPU Environment: Using RaNER and REX-UniNLU
After going through numerous iterations, I ultimately returned to focus intensively on two specialized models from the Alibaba ecosystem: RaNER and REX-UniNLU.
RaNER (Base-Generic) was originally the first model I downloaded, but it has significant shortcomings in long-text processing, with default support limited to only 512 Tokens. However, looking across the Chinese NLP community, various evaluation datasets show that RaNER delivers the strongest performance; the 400MB general-purpose Base version can achieve 91% accuracy in recognizing personal names, place names, and organizations. Although during my testing I found that it might not reach such a high ratio in the legal domain, considering that my final application approach adopts a “NER desensitization + manual confirmation + guardrail review” method, in practice, only two NER models with different logics are needed to achieve higher accuracy.
REX-UniNLU (DeBERTa-v3) was something I accidentally discovered while testing Siamese-UniNLU; it should serve as a replacement project for Siamese and natively better addresses the long-text input problem. However, since this model is also a 400M general-purpose model, it can not only handle NER tasks but also perform relation, fact, and sentiment extraction, making it quite suitable for use as a data guardrail reviewer in later stages. It is highly sensitive in capturing colloquial expressions and complex nested entities, effectively compensating for the rigidity of traditional NER models in boundary determination. Moreover, during this process, I introduced the strictest entity extraction mode, which can almost extract all names of entities that are “suspected” to be entities.
Online VPS Environment: Using ckiplab-albert-tiny-chinese-ner and SpaCy
If RaNER + REX aims to pursue ultimate accuracy on a PC with 16GB of RAM, then when I shift my focus to a Synology NAS with 4GB of RAM, or an inexpensive VPS with only 1 core and 2GB, this “heavy armor” setup simply cannot run. In such extreme environments, my favorite combination is ckiplab-bert-tiny-chinese-ner paired with SpaCy.
ckiplab-albert-tiny is less than 15MB in size; its role is to leverage BERT’s residual semantic capabilities to “pre-filter” the most obvious, well-formatted personal names and place names in the text within milliseconds. Although it may miss complex colloquial expressions, its extremely low computational cost frees up resources for subsequent processing stages.
Next, I introduced SpaCy (zh_core_web_md). The advantage of SpaCy lies not in how “smart” it is, but in its extremely high industrial stability. As an NLP framework implemented based on Cython, it performs very robustly when handling administrative divisions and basic organization names. By chaining these two models together—one responsible for rapid initial processing, the other for maintaining baseline accuracy—combined with my “human-machine review” logic, a solid data security guardrail can still be constructed even in low-power environments.