
After the redesign, the Southern Weekly website discontinued its RSS subscription service, causing significant inconvenience for many netizens who rely on RSS readers for their daily reading.
The RSS feeds for Southern Weekly that can be found online (such as those from XianGuo, NewsBlur, Feedburner, etc.) are essentially from the pre-redesign era and only output old articles from before the redesign.
As a heavy user of RSS readers, I decided to search for custom RSS scraping services to solve the Southern Weekly RSS subscription issue. I discovered that feed43.com, a website that has been operating for 8 years, still offers free custom RSS scraping services. This is truly a gem in the industry (compared to the likes of Google Reader, which was a letdown).
So, I registered an account on feed43.com and began editing the RSS scraping code for Southern Weekly.
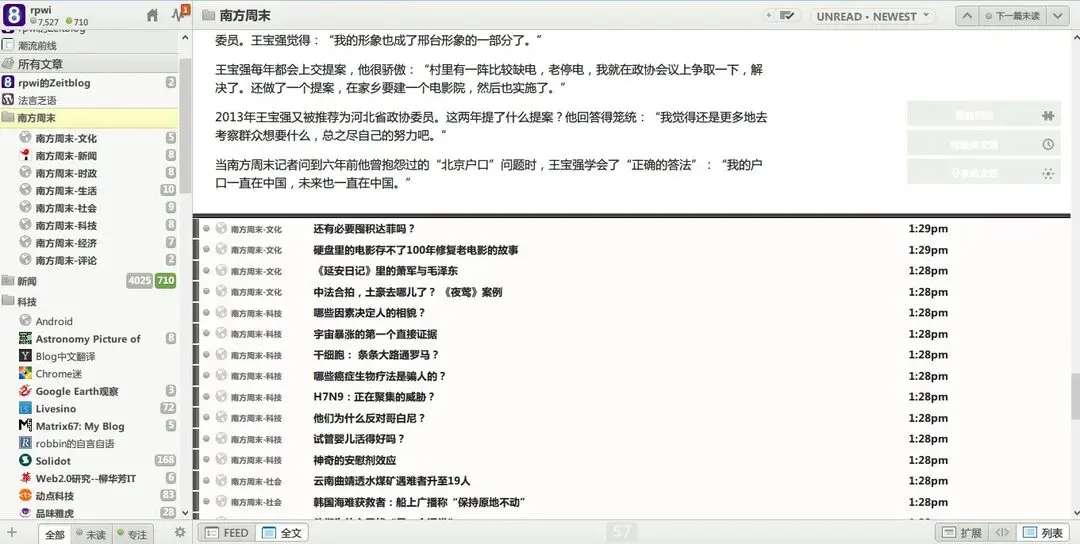
After some investigation, I found that Southern Weekly’s primary article categories are divided into nine sections: News, Culture, Technology, Pictures, Society, Economy, Society, Commentary, and Politics (the “Pictures” category hasn’t been updated for over a year, likely a leftover issue from the redesign). The web addresses for these nine pages are /contents/5 to /contents/13.
After noting all the URLs, I added them one by one on feed43 (see the end of the article) and obtained the corresponding RSS feed addresses in XML format, which can be edited for titles and link names.
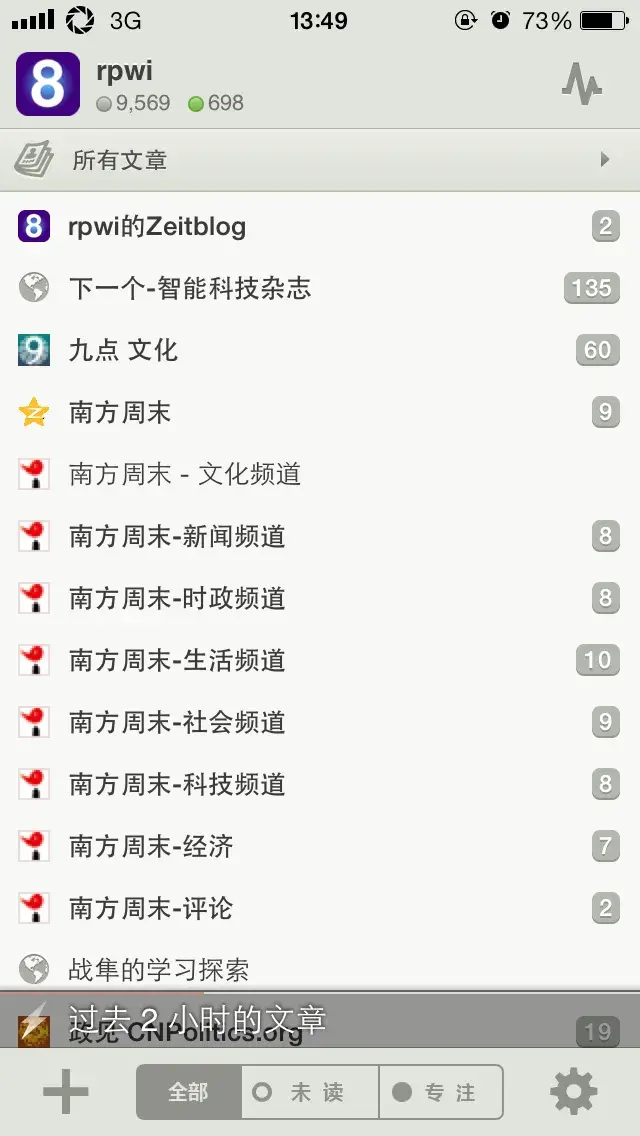
Here are the eight RSS feeds I created:
<opml version="1.0">
<head><title>Southern Weekly</title></head>
<body>
<outline text="Southern Weekly">
<outline text="Southern Weekly - Culture" xmlUrl="http://feed43.com/infzmclut.xml"/>
<outline text="Southern Weekly - News" xmlUrl="http://feed43.com/infzmnews.xml"/>
<outline text="Southern Weekly - Politics" xmlUrl="http://feed43.com/infzmpolitcs.xml"/>
<outline text="Southern Weekly - Life" xmlUrl="http://feed43.com/infzmlife.xml"/>
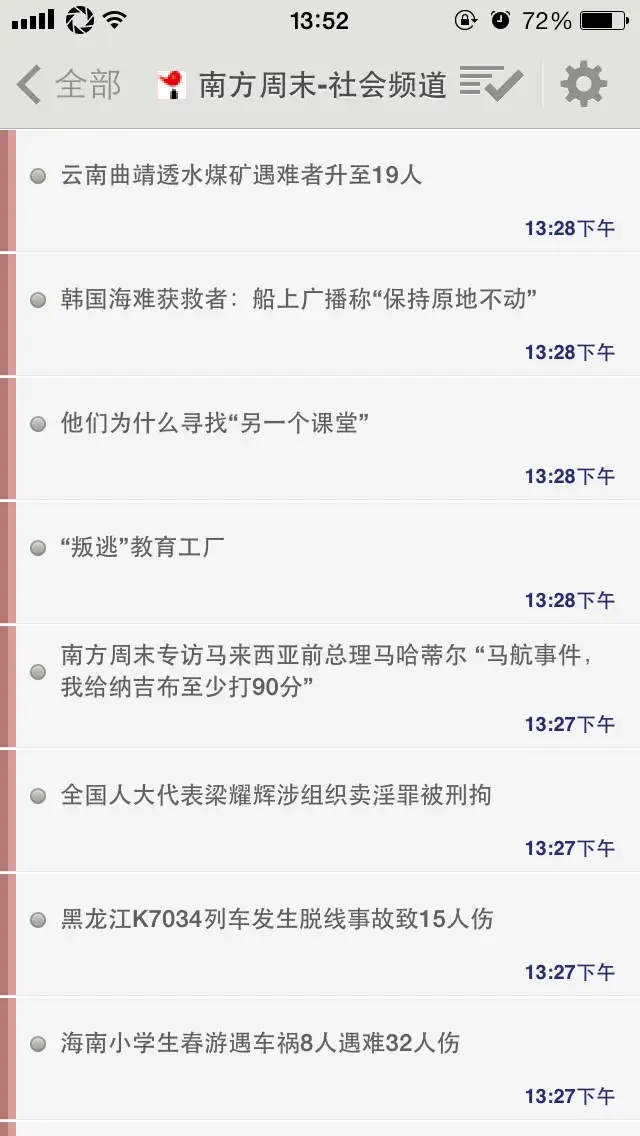
<outline text="Southern Weekly - Society" xmlUrl="http://feed43.com/infzmsocio.xml"/>
<outline text="Southern Weekly - Technology" xmlUrl="http://feed43.com/infzmtech.xml"/>
<outline text="Southern Weekly - Economy" xmlUrl="http://feed43.com/infzmeco.xml"/>
<outline text="Southern Weekly - Commentary" xmlUrl="http://feed43.com/infzmcomments.xml"/>
</outline>
</body>
</opml>
Copy the above code into a text editor, save it as an *.xml file, and you can import it into various RSS readers. Alternatively, you can directly copy the links in the middle, such as the RSS page address for “Politics,” which is feed43.com/infzmpolitcs.xml.
Of course, since feed43 can only scrape updates from a fixed page, the articles captured here only include titles and brief content. For full-text RSS output, you would need to rely on the scraping functions of various RSS readers, such as those supported by NewsBlur’s premium users. If you want to achieve full-text scraping for free, you can try using NewsBlur or the mobile client of NewsZeit. Although full-text webpage output is a premium feature for these RSS service providers, there are no such restrictions on their mobile clients. The only issue is that the mobile client only supports 64 RSS feeds. I personally recommend that heavy RSS users consider purchasing the premium services of NewsBlur or NewsZeit, which cost $24 or 50 RMB per year, which is not expensive.
The effect on the reader is as follows:
Web page on a computer
Mobile client interface
Mobile client interface

Mobile client interface
FEED43.com subscription code addition section:
Southern Weekly webpage source code:
<article class="listContent clearfix">
<div class="articleTitle"><h><a href="http://www.infzm.com/content/100060" target="\_blank">"One Hundred Years of Solitude" Author Gabriel García Márquez Passes Away</a></h></div>
<div class="clearfix">
<div id="left" >
<p class="articleInfo" style="width:100%">Author: Comprehensive 2014-04-18 12:40:22</p>
<p class='intro' style="width:100%">
<a href="http://www.infzm.com/content/100060" target="\_blank">"In the world created by García Márquez, death may be the most important behind-the-scenes director. However, the melancholy emotions conveyed through his works, while being eerie and vivid, also exhibit a sense of vitality." — 1982, Gabriel García Márquez won the Nobel Prize in Literature, and this was the citation. Gabriel García Márquez passed away on the afternoon of April 17 due to illness, at the age of 87.</a></p>
Extraction code: {%} represents the dynamic part to be extracted, {*} represents the omitted part.
<div class="articleTitle">{\*}href="{%}"{\*}target="\_blank">{%}</a>{\*} style="width:100%">{%}</p>{\*} href="{%}" target="\_blank">{%}</a>
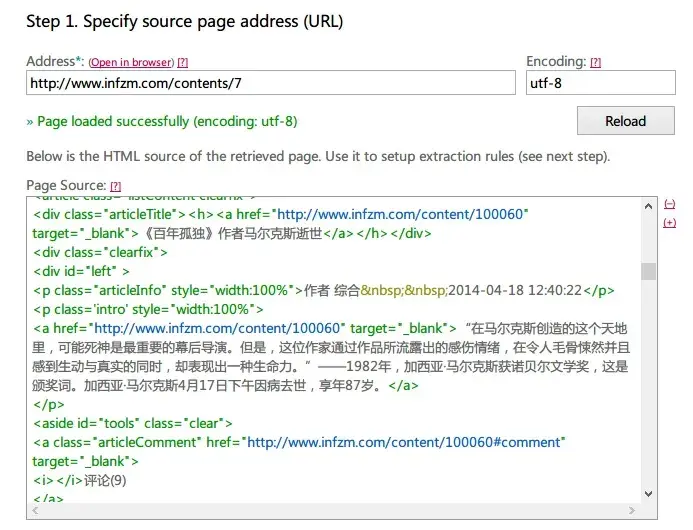
Step 1: Add the page address to subscribe to, set to UTF-8 encoding.
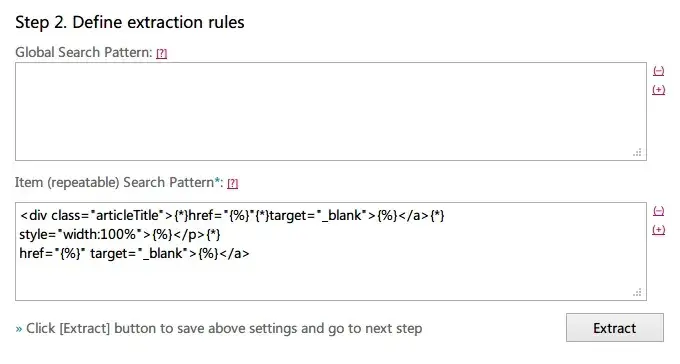
Step 2: Edit the title, link, and article content extraction code.
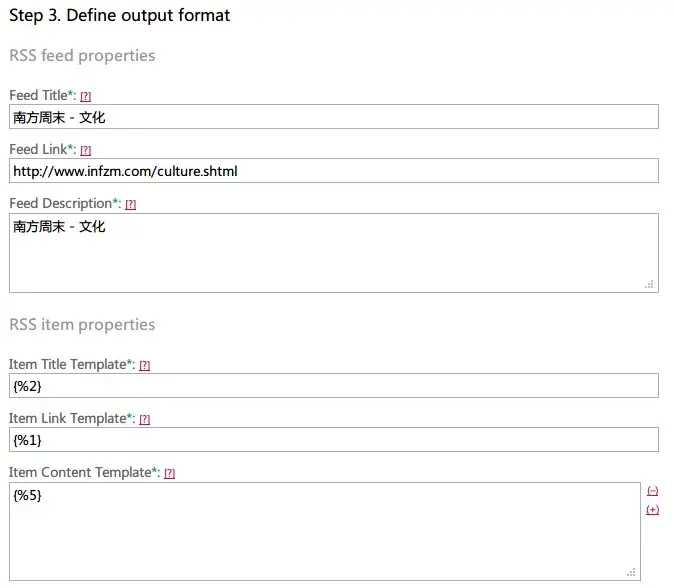
Step 3: Fill in the RSS feed information and the code for extracting content.